Attaching a RAG-based AI chatbot to an open source document site
A practical guide to adding a RAG chatbot to open source docs, covering model choice, retrieval pipeline design, and cost-aware operations.
7 min readaifirsttx
Published
Dec 01, 2025
Reading time
7 min
Sections
18
On this page18+-
Reasons for introducing AI chatbot into open source documents
Firsttx is an open source consisting of three layers: Prepaint, Local-First, and Tx.
Prepaint solves blank screen issue when revisiting CSR React app.
Local-First is an IndexedDB-based data layer.
Tx is a library that manages optimistic updates as transactions.
The role of each package is clear, but the concept of using the three in combination may be unfamiliar. Although I wrote the document, I was still left wondering, “Will it be easy for someone seeing it for the first time to get started?”
Meanwhile, after seeing the recent increase in RAG-based document chatbots, I thought it would be a good idea to add it to Firsttx documents as well. In this article, we share the process of actually implementing an AI chatbot.
Which technology did you choose and why?
How did you build the RAG pipeline?
How were costs and operations considered?
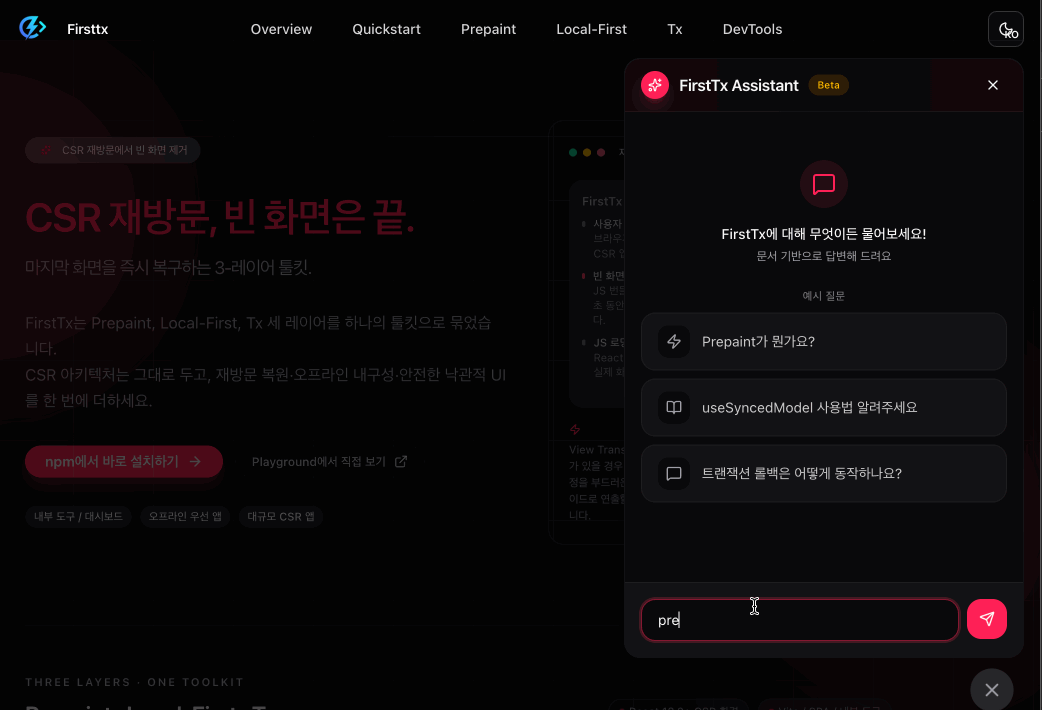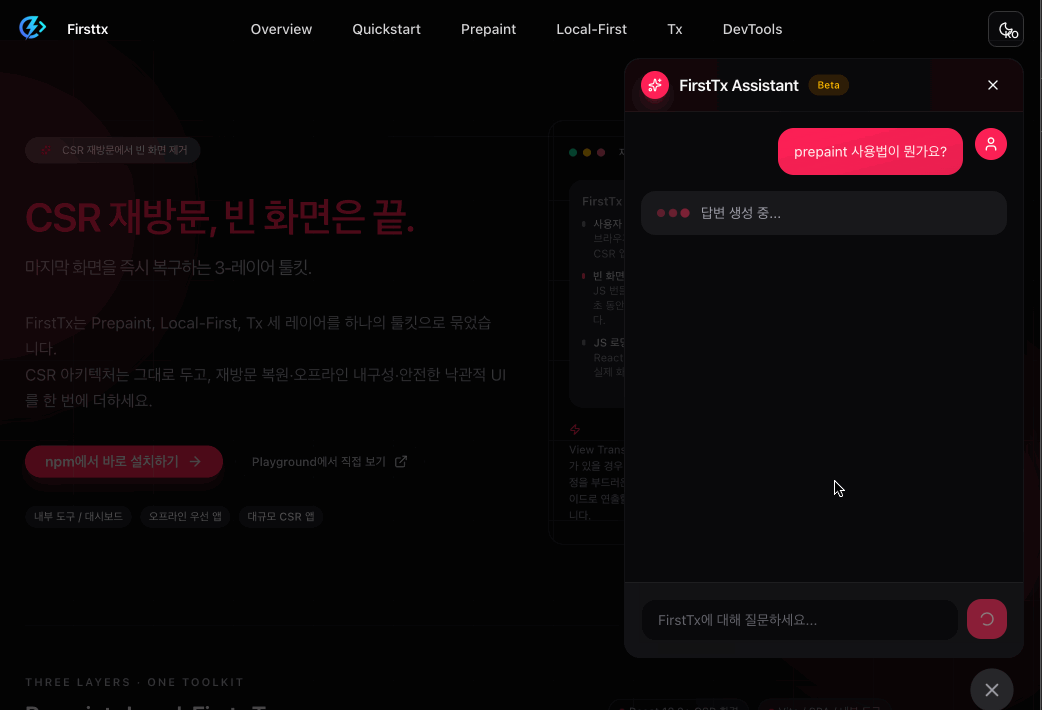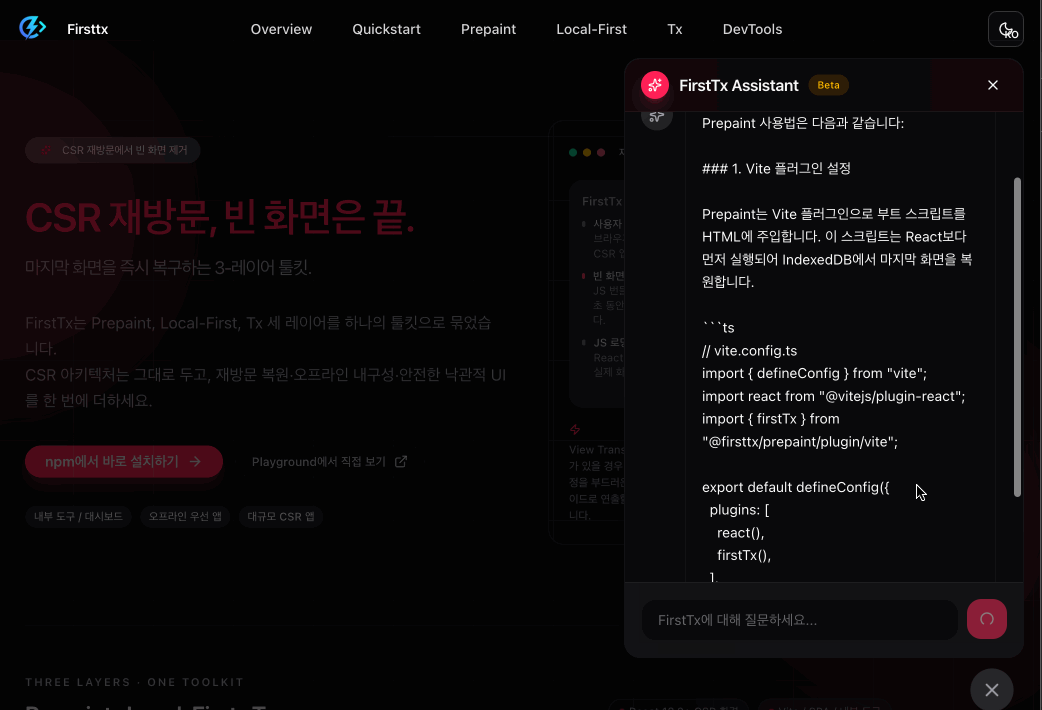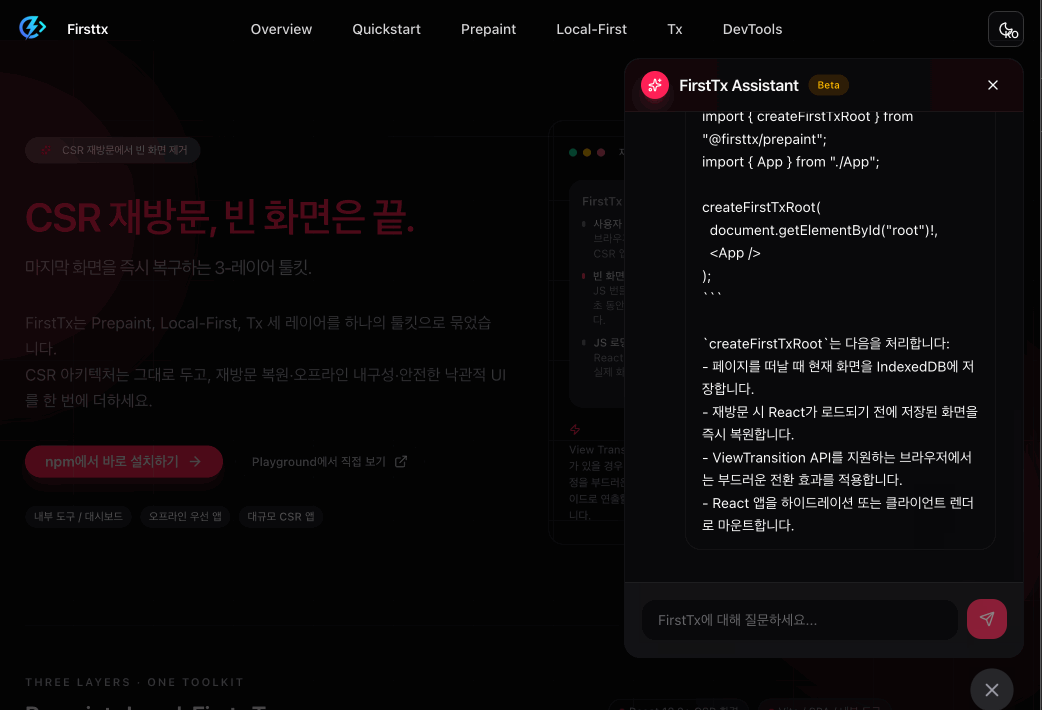
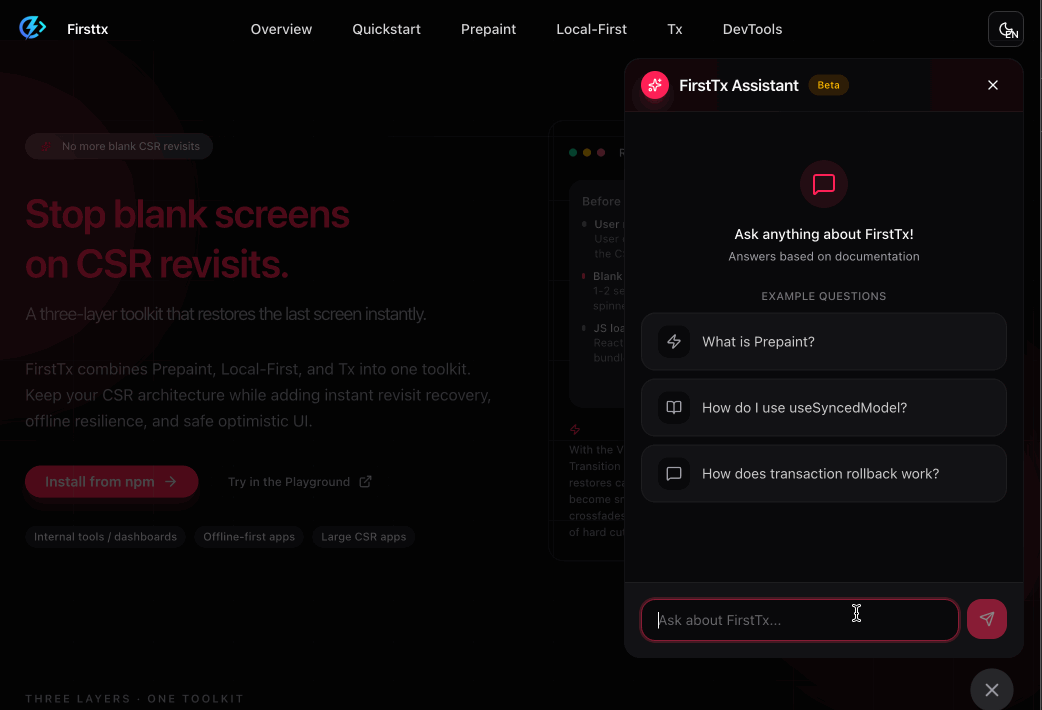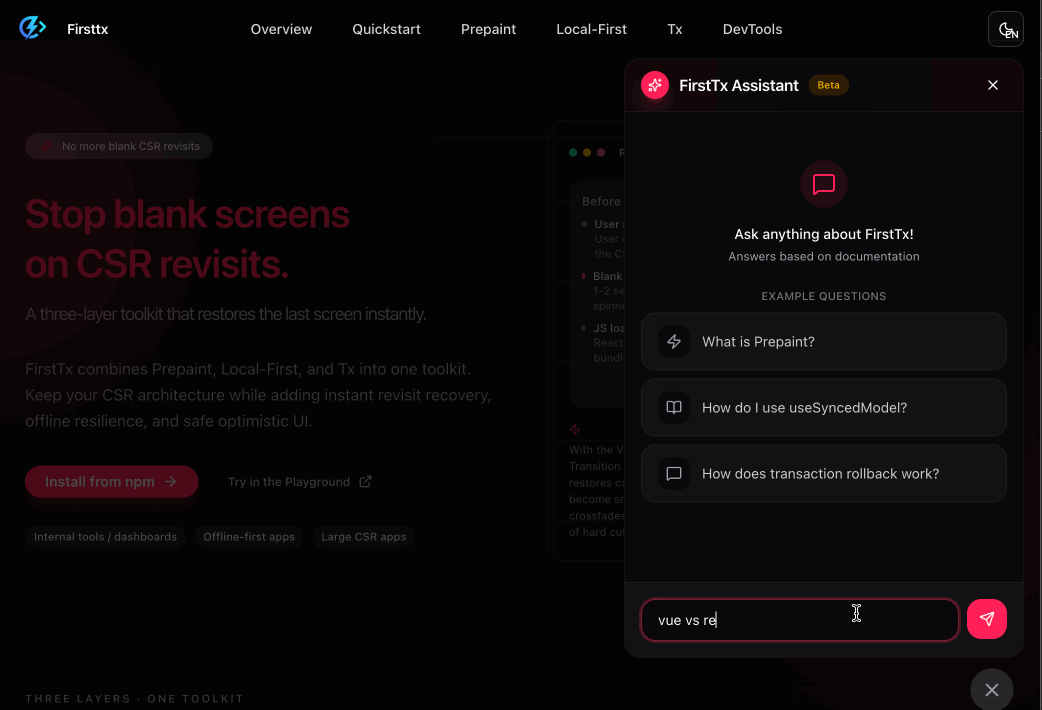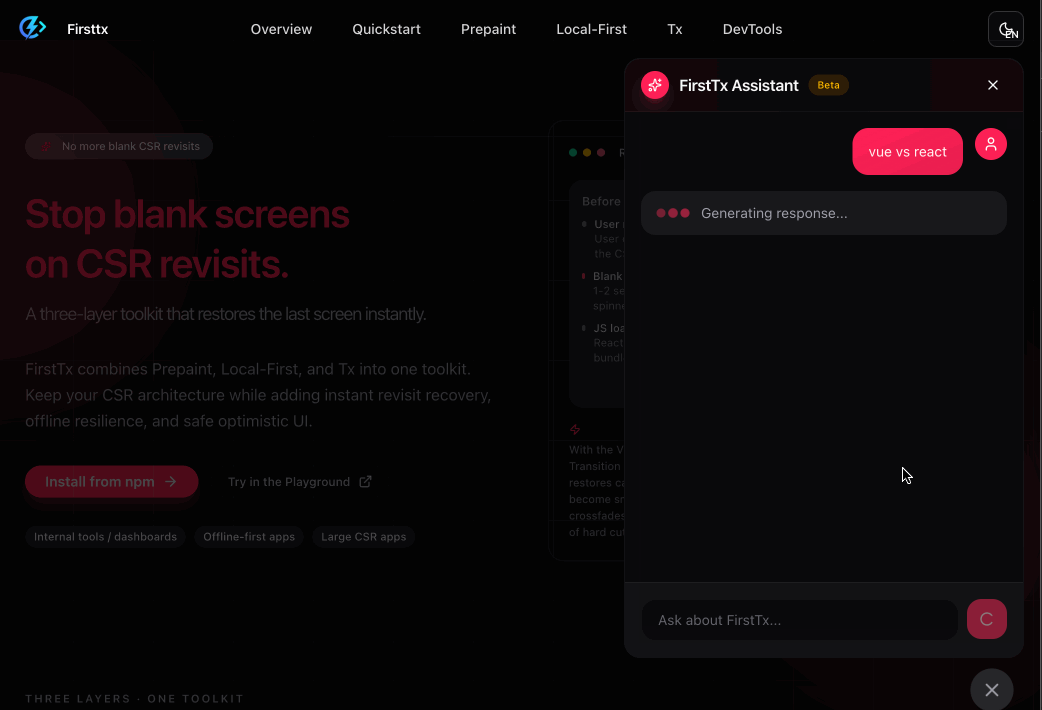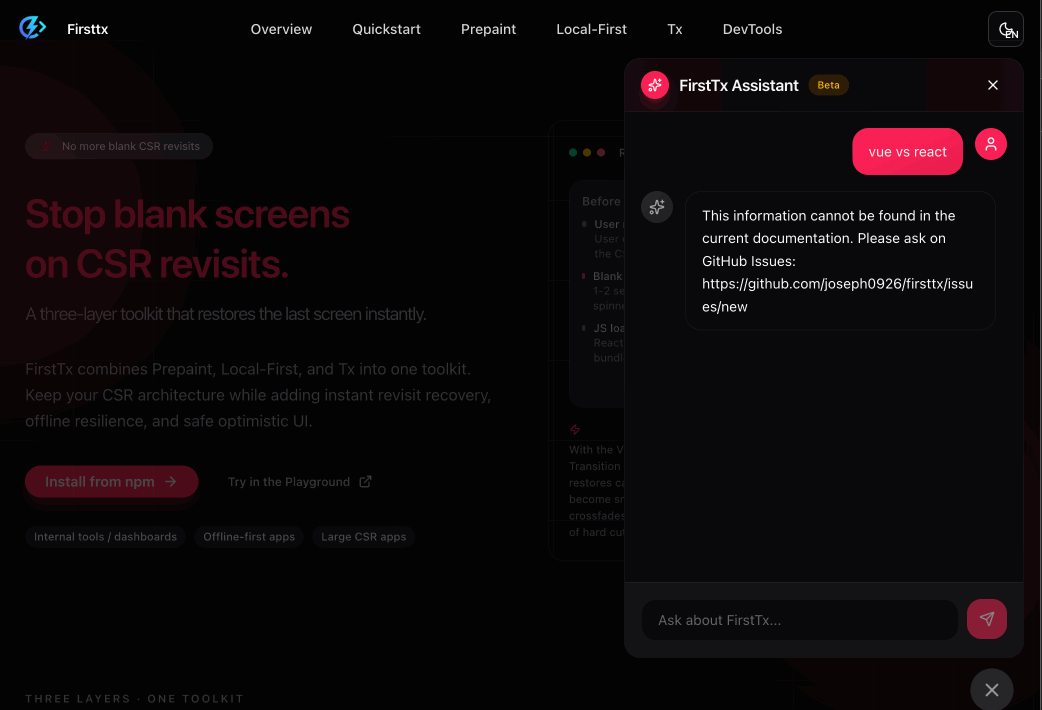
The completed chatbot operates as follows.
When asking questions related to Firsttx - RAG based response
When asking unrelated questions - scope information
Model Selection - Reason for choosing gpt-4o-mini
The first thing to decide when implementing an AI chatbot was “which model” to choose.
Main purpose is retrieved document-based answers rather than complex reasoning.
Token usage per question is not large
Usage expected to be approximately 50 to 100 times per day
Output is more important than input (short question → long answer)
The last point was especially important. gpt-5-mini has a cheap input, but its output is $2.00, which is more than three times that of gpt-4o-mini ($0.60).
In cases where the answer is long, such as a document chatbot, the output cost accounts for most of the total cost, so gpt-4o-mini was judged to be the most reasonable.
Building a RAG pipeline - Document -> Vector -> Search
What is RAG?
LLM basically allows you to answer questions about “what you know.” In other words, because it is not generally known like Firsttx and there is no data for newly created information, LLM produces strange answers by making answers impossible or non-existent.
To solve this, we search documents related to the question and provide them as context to LLM, and LLM is able to use that data to answer what it did not know.
General: Firsttx question -> LLM -> answer (say you don’t know or give an irrelevant answer)
The problem is that computers cannot directly compare the meaning of text. That's why we do embedding.
What is embedding?
As mentioned earlier, computers cannot directly compare the meaning of text. So, after converting the text to numbers, we find and return the vector related to the question.
For example, the text "Prepaint solves blank screen issues in CSR apps" is converted to [0.023, -0.156, 0.891, ...] (1,536 numbers).
Now, if a user asks, "I see a white screen when I revisit," this question will also be converted to a vector, and since the two vectors are semantically similar, we can find relevant documentation.
If it was a keyword search, "blank screen" and "white screen" would not have matched because they are different words.
Additionally, a dedicated DB that stores these embedding vectors and quickly searches for similar vectors is called Vector DB.
What is Vector DB?
What is similar to a regular DB is that it stores and reads data.
However, the key difference is that a general DB can only search for exact matches or inclusions, and it is impossible to find semantically similar values.
For example,
General DB: WHERE content LIKE '%blank screen%' → "white screen" and "blank page" are not found
Vector DB: Search for “blank screen” → Find all “white screen”, “blank page”, and “nothing visible”
This Semantic Search is the core of RAG.
Actual implementation
Based on this concept, it was actually implemented as follows.
Free tier is sufficient for 10,000 requests per day
Redis can also be used with the same account (Rate Limiting, used for caching)
Indexing Pipeline
This is the process of saving documents in vector DB. This task only runs once when the document changes.
Document (markdown) → Chunking → Embedding → Save Upstash Vector
Chunking is the process of dividing a document into appropriate sizes. Since embedding the entire document reduces search accuracy, we split it into sections.
I chose heading based chunking. Since the MDX document was already logically divided into H1/H2/H3, I used this structure as is.
function chunkMarkdown(content: string, docId: string): Chunk[] {
const lines = content.split('\n');
const chunks: Chunk[] = [];
let currentH1 = '';
let currentH2 = '';
let currentH3 = '';
let currentContent: string[] = [];
function saveChunk() {
const text = currentContent.join('\n').trim();
if (text.length > 0) {
chunks.push({
id: `${docId}-${chunks.length + 1}`,
title: currentH1,
section: currentH3 || currentH2 || currentH1,
content: text,
});
}
currentContent = [];
}
for (const line of lines) {
// Check more specific patterns (###) first
if (line.startsWith('### ')) {
saveChunk();
currentH3 = line.slice(4);
} else if (line.startsWith('## ')) {
saveChunk();
currentH2 = line.slice(3);
currentH3 = '';
} else if (line.startsWith('# ')) {
saveChunk();
currentH1 = line.slice(2);
currentH2 = '';
currentH3 = '';
} else {
currentContent.push(line);
}
}
saveChunk(); // Save last section
return chunks;
}
Search Pipeline
When a user question comes in, it goes through the following process:
Question → Embedding → Search Upstash Vector → Relevant chunks → Pass as context to LLM
The retrieved chunks are included in the system prompt and delivered to LLM.
const systemPrompt = `
You are a Firsttx document assistant.
Please refer to the document below to answer your questions.
## Reference document
${chunks.map((c) => `### ${c.section}\n${c.content}`).join('\n\n')}
`;
API & UI implementation - AI SDK 5 applied
Select AI SDK
I used Vercel's AI SDK. Version 5 is the latest and has good integration with Next.js.
pnpm add ai @ai-sdk/react @ai-sdk/openai
API Route implementation
Implemented chatbot API with Next.js App Router's Route Handler.
// app/api/chat/route.ts
import { streamText, convertToModelMessages, type UIMessage } from 'ai';
import { chatModel } from '@/lib/ai/openai';
import { retrieveContext, buildSystemPrompt } from '@/lib/ai/rag';
export async function POST(req: Request) {
const { messages }: { messages: UIMessage[] } = await req.json();
// Extract questions from last user message
const lastUserMessage = messages.findLast((m) => m.role === 'user');
const userQuery =
lastUserMessage?.parts
?.filter((part) => part.type === 'text')
.map((part) => part.text)
.join(' ') || '';
// RAG: Search for related documents
const { contextText } = await retrieveContext(userQuery);
const systemPrompt = buildSystemPrompt(contextText);
// Call LLM (Streaming)
const result = streamText({
model: chatModel,
system: systemPrompt,
messages: convertToModelMessages(messages),
});
return result.toUIMessageStreamResponse();
}
Since the document site supports Korean/English, the chatbot also had to support multiple languages.
Use of Vector DB Namespace
Instead of creating separate indexes for each language, we used Upstash Vector's Namespace feature.
// When indexing
index.namespace('ko').upsert(koChunks);
index.namespace('en').upsert(enChunks);
// When searching
index.namespace(locale).query({ vector, topK });
Why we chose Namespace
Metadata filtering has a “filtering budget” limit.
Namespace is more efficient by separating the search space itself
Can be managed within a single index without additional cost
Multilingual system prompts
const SYSTEM_PROMPTS = {
en: (context: string) => `You are a FirstTx document assistant.
Please refer to the document below and answer in Korean.
${context}`,
en: (context: string) => `You are the FirstTx documentation assistant.
Answer in English based on the following documents.
${context}`,
};
Estimated Cost
item
Estimated monthly cost
OpenAI API
~$5
Upstash Vector
Free (10K/day)
Upstash Redis
Free (10K/day)
Vercel
~$20 (Pro)
Total
~$25
Based on 50 to 100 uses per day, the low price of gpt-4o-mini allowed us to keep
our LLM costs below $5 per month.
Results & Retrospective
Lessons Learned
1. RAG is simpler than you think
It looks complicated, but the key is “Retrieve → Inject context → Call LLM”. Implementation was easy thanks to good libraries (AI SDK, Upstash).
2. Chunking strategy is important
Heading-based chunking makes good use of document structure. Search accuracy largely depends on chunking quality.
3. Namespace is better than metadata filtering
Metadata filtering has limitations when supporting multiple languages. It is more efficient to separate the search space by Namespace.
Things to improve in the future
Added feedback button (helpful/not helpful)
Caching of same question responses
Token Usage Dashboard
Attaching an AI chatbot to a document was not as difficult as I thought. Thanks to Upstash's free tier and gpt-4o-mini's low price, you can run it for less than $25 per month.
I hope this helps those who have similar concerns.